Flattening 8,000-file Android APKs into a single Parquet table
A research tool that lets non-engineers grep across years of Android apps in seconds. AppInspect, built for the SFB 1187 platform-studies group at Siegen.
Live at appinspect.phil.uni-siegen.de — the Siegen-hosted instance. Code at jason-chao/appinspect-worker. Notes from building AppInspect.
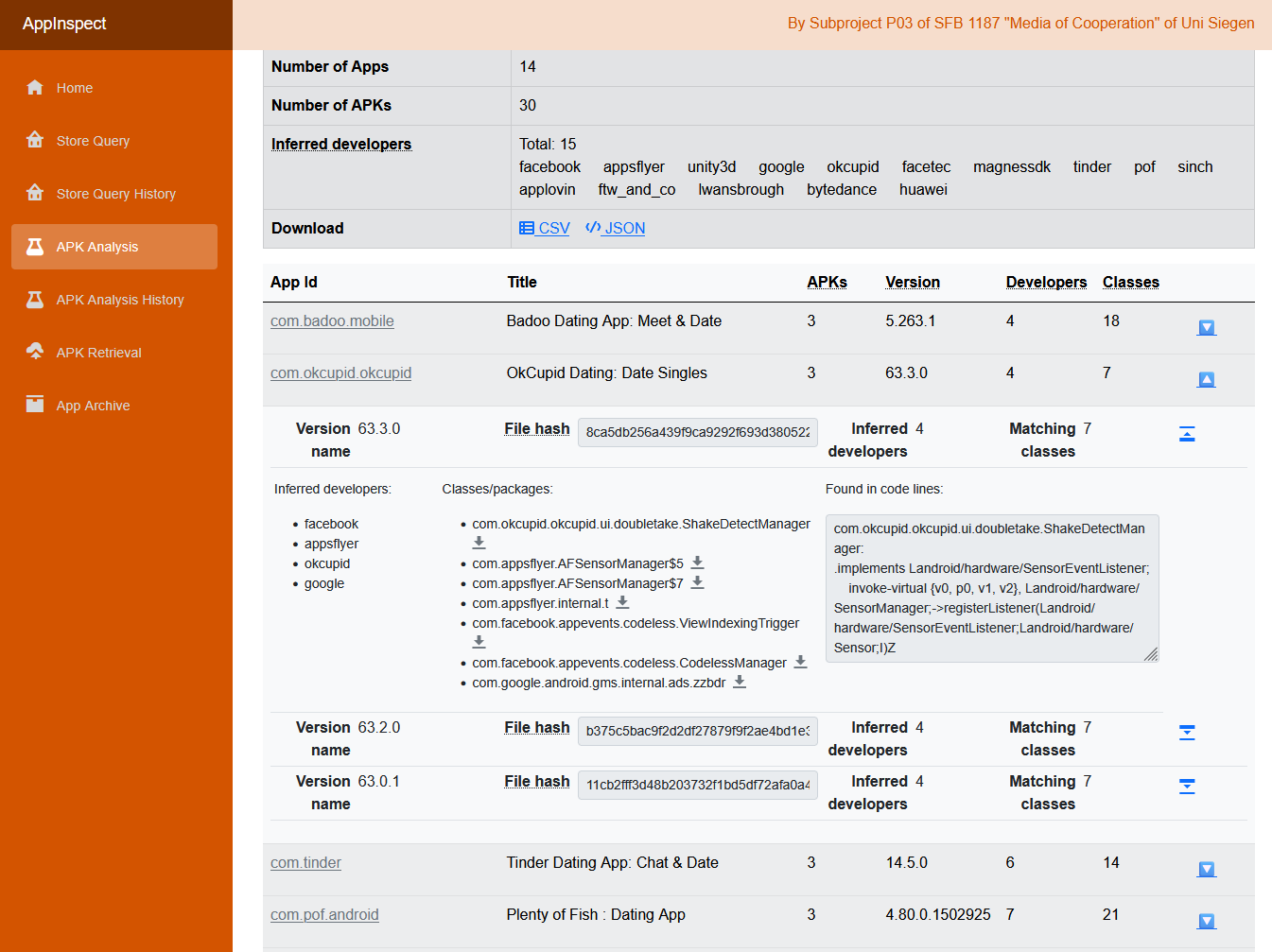
Between 2021 and 2023, at the SFB 1187 “Media of Cooperation” (University of Siegen), I built AppInspect for media- and platform-studies researchers. The target question: “how have TikTok’s permissions evolved across versions in China vs. the international market?” — answered in seconds, not days.
The engineering problem was a small-file-I/O problem, handled by flattening the decoded APK corpus into a single columnar table.
What’s inside an APK, and why it matters
Before the engineering: a one-screen tour of what’s in an Android .apk, because every later decision turns on it.
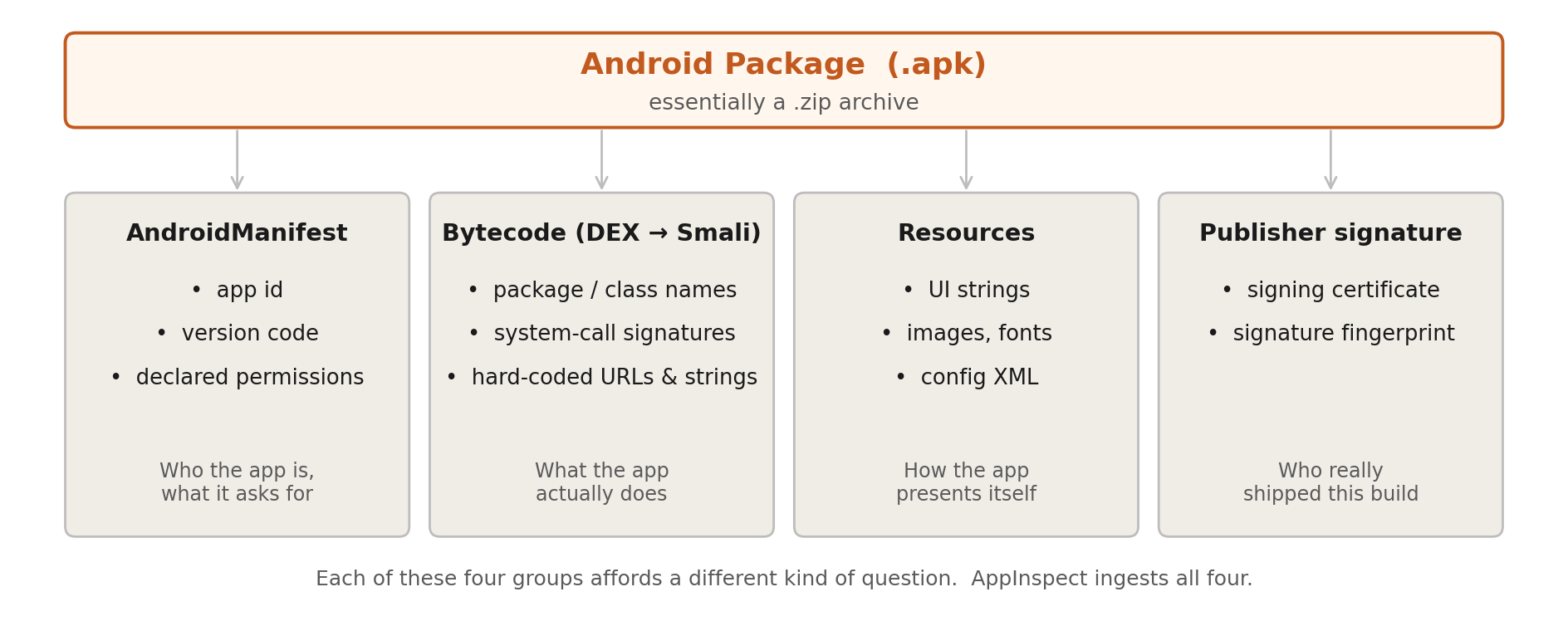
Four groups, four kinds of question. AppInspect ingests all four — the trick was making them queryable at corpus scale.
The problem nobody warns you about
An Android APK is just a zip file. So is a .docx, so is a .jar. Open one with unzip and you get a polite handful of files: a manifest, some resources, one or two classes.dex. Easy.
The problem starts when you actually want to look inside the bytecode. The standard move is to disassemble it with apktool, which expands the DEX bytecode into Smali — a human-readable assembly dialect — and unpacks every embedded resource. One real example from the AppInspect corpus:
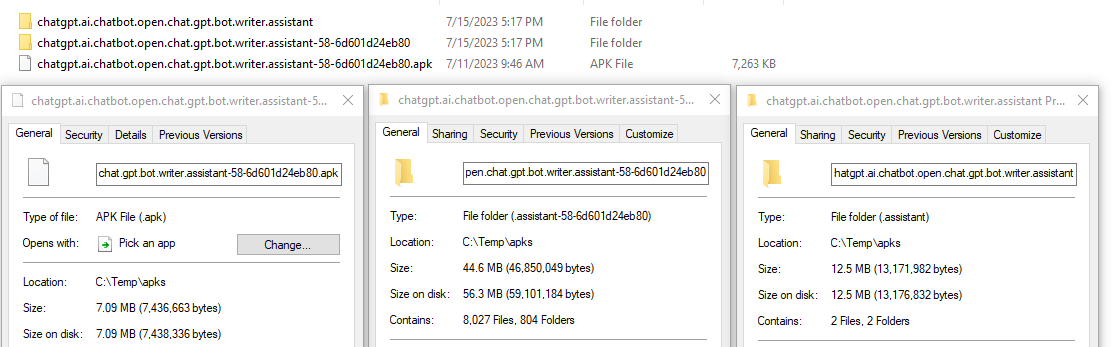
A 7.09 MB ChatGPT-clone APK becomes 8,027 files across 804 folders, weighing 44.6 MB on disk. Of those 8,027 files, the vast majority are tiny Smali files — one per Java/Kotlin class — many under a kilobyte.
Now multiply that by hundreds of apps and dozens of historical versions per app. You’re suddenly running a corpus of millions of small files, and any filesystem you point at it will protest. On the ext4 volumes I was using, scanning the disassembled code of a single APK with naive grep -r took 3 to 5 minutes. Researchers wanted to scan hundreds of apps per query. The arithmetic was hostile.
This wasn’t a CPU problem. It was an I/O problem. Anybody who has tried to rsync a node_modules directory has met its smaller cousin: the per-file overhead — open, stat, seek, close — dominates the actual reading. Parallelism doesn’t help much when the bottleneck is the inode lookup.
What researchers actually wanted to ask
Before describing the fix, here’s the shape of the questions the tool needed to answer. They came from collaborators in the Digital Methods Initiative Winter School 2022 and from the SFB 1187 group:
- Which third-party trackers ship inside this app, and how has the list changed across versions?
- Does this app declare a SensorEventListener? (i.e. can it read the gyroscope or accelerometer without asking for a permission?)
- Which hard-coded URLs and SDK class names appear in this version that weren’t in the previous one?
- Is the certificate signing this APK the same certificate that signed the version published two years ago?
Each question is, at its core, a substring search across a labelled corpus of decoded files, with version and app-ID as the labels. None of them needs a call graph or a taint analysis. (More on that limitation later.)
So the engineering job was: make substring search across the corpus feel cheap.
The fix: collapse the filesystem into a Parquet table
The key move is embarrassingly simple in retrospect. Instead of letting decoded APKs sprawl across the filesystem, I flattened them into a single Apache Parquet table. One row per file inside one version of one APK. Columns capture the metadata; the file contents themselves go into either a text column or a blob column.
The schema:
| Column | Type | What it holds |
|---|---|---|
app_id | string | App identifier from AndroidManifest.xml |
version_code | integer | Version code from AndroidManifest.xml |
version_name | string | Human-readable version name |
apk_sha256 | string | SHA-256 of the whole APK (catches tampering with same code) |
relative_path | string | File’s path inside the decoded APK |
filename | string | Base filename |
extension | string | File extension (smali, xml, png, …) |
content_text | string | Text content (Smali, XML, JSON, …) — NULL if binary |
content_blob | bytes | Binary content (PNG, font, native .so) — NULL if text |
content_mode | string | "text" or "blob" — used as the partition key |
file_sha256 | string | SHA-256 of this individual file |
Five things this schema buys you, none of which is obvious until you try the alternatives:
- Columnar reads. A Smali substring scan only needs
app_id,version_code,relative_path, andcontent_text. Parquet reads only those columns from disk. Thecontent_blobcolumn — usually the heaviest — never enters memory. - Compression where it matters most. Disassembled Smali is enormously repetitive: every method begins with the same tokens (
.method,.locals,invoke-virtual,Landroid/...). Parquet’s per-column dictionary encoding plus Snappy collapses that down to a fraction of the on-disk size. - Longitudinal queries are free. Because every version of every app shares one table, “show me how
SensorEventListenerreferences changed across TikTok versions from 2017 to 2022” is aWHERE app_id = 'com.zhiliaoapp.musically' AND content_text LIKE '%SensorEventListener%'away. - Tamper detection by construction. I keep both the per-APK SHA-256 and the per-file SHA-256. Two APKs published with the same
version_codebut different bytes (which happens — including for malicious reasons) become distinguishable rows, not silently merged blobs. - De-duplication, almost for free. Most of the files inside successive minor versions of an app are byte-identical. If you key your downstream analyses on
file_sha256you skip the duplicates without having to think about it.
I partition the table on content_mode so the text-column workload (the common case) doesn’t have to skip past binary blobs:
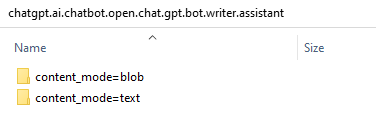
…and inside each partition, Parquet does the rest:
A single 9.6 MB Parquet file replaces the thousands of Smali files for one app’s entire history. Order-of-magnitude figures only — I never built a proper benchmark harness, and that’s a gap I would close if I were doing this again — but in practice, scanning a hundred decoded APKs went from “go make coffee” to a few seconds on a 5-node PySpark cluster of small VMs.
The pipeline, end to end
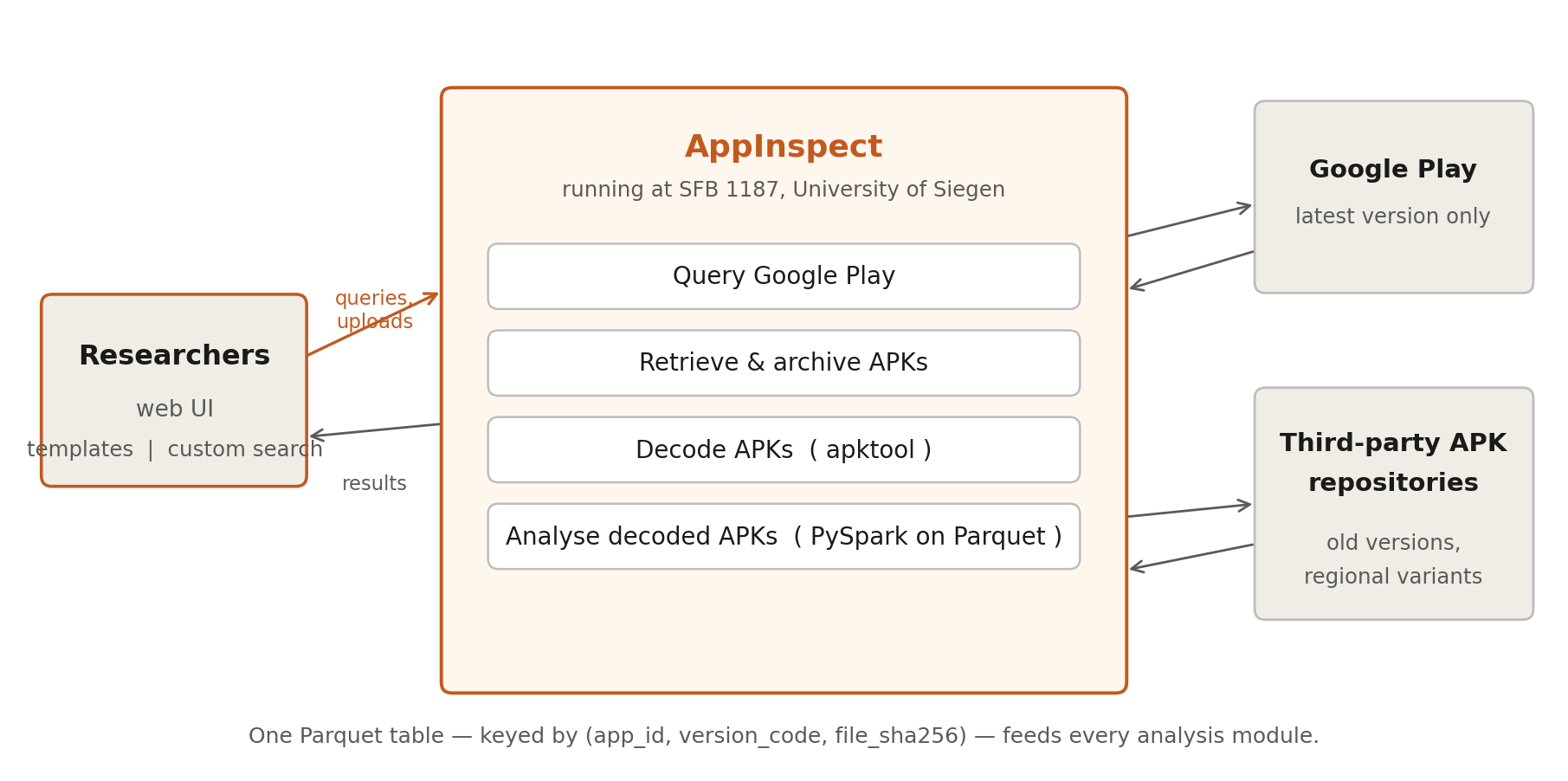
Three deliberate choices inside this pipeline are worth naming:
Decoupling decode from query. Decoding with apktool is slow and single-threaded per APK. Querying via Spark is fast and embarrassingly parallel. Keeping them on opposite sides of the Parquet table means we decode each APK exactly once, ever, and amortise the cost across every future query.
Horizontal over vertical. It would have been cheaper, short-term, to ask the IT department for a single beefy machine. But scaling out to a small cluster of cheap VMs meant we could pull more nodes in for a workshop week and shrink back afterwards. For a research group that runs in bursts (Winter School, paper deadline, Winter School again), that elasticity matters more than peak per-node throughput.
Two tiers of UI. The web frontend exposes both analysis templates (a one-click Permission Scan, Tracker Scan, Code Scan, Signature Comparison) and a lower-level custom text search with extension filters and version pickers. Templates lower the floor for researchers who don’t write code; custom search raises the ceiling for those who do. The same Spark queries underpin both.
What it enables — and a caveat
Three example results from the DMI 2022 cohort, all of which fall out of the same WHERE content_text LIKE '%…%' GROUP BY app_id, version_code shape:
TikTok’s permission profile diverges between markets. Looking at the historical APKs of TikTok’s Chinese version (Douyin) and the international version, the Chinese variant shows a sharp rise in manufacturer-custom permissions starting around 2019 — visible as the white “other permissions” band:
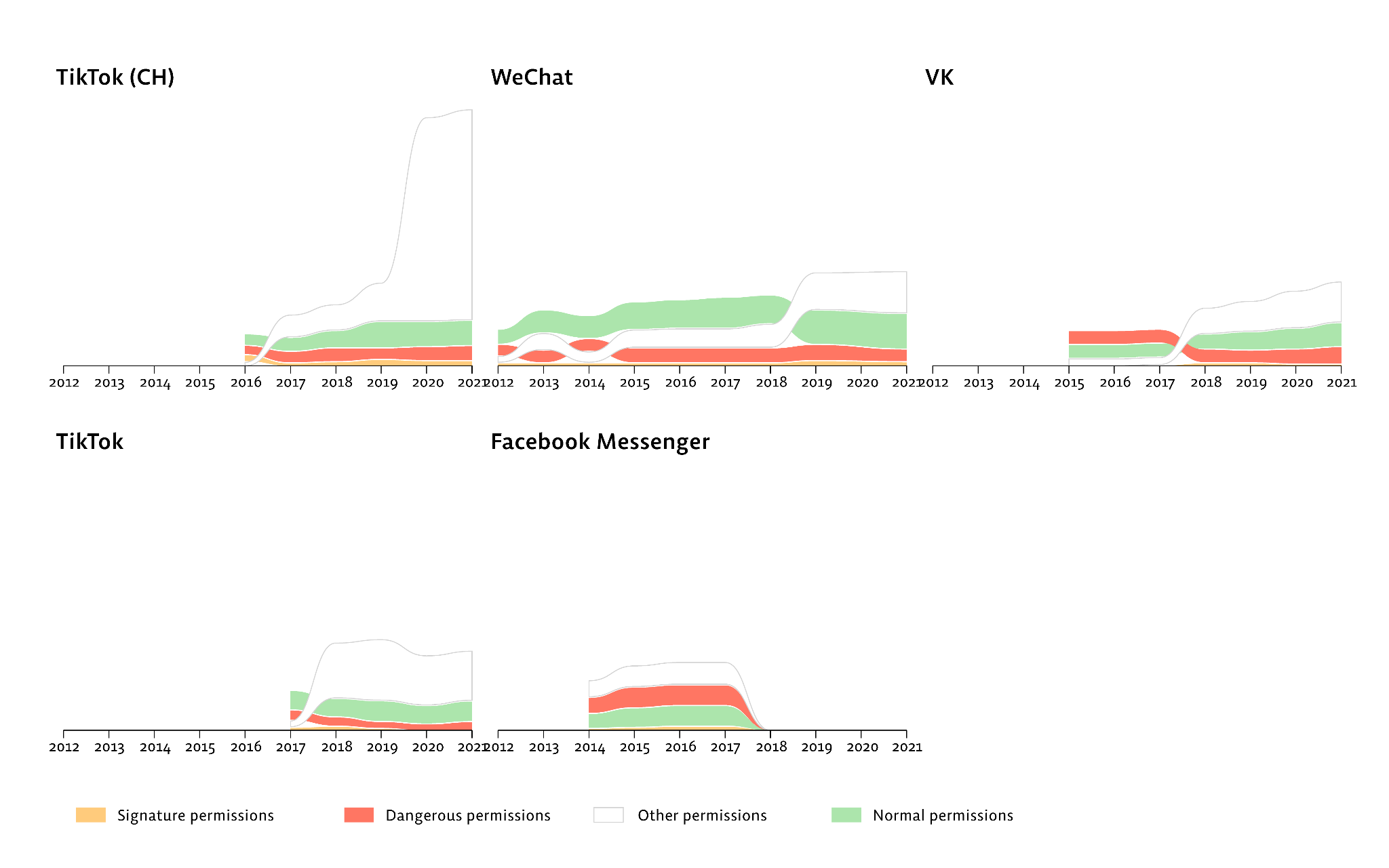
App size grows in step. Plotting APK filesize over time across China and international variants shows the two builds diverging in ways that are hard to explain by features alone:
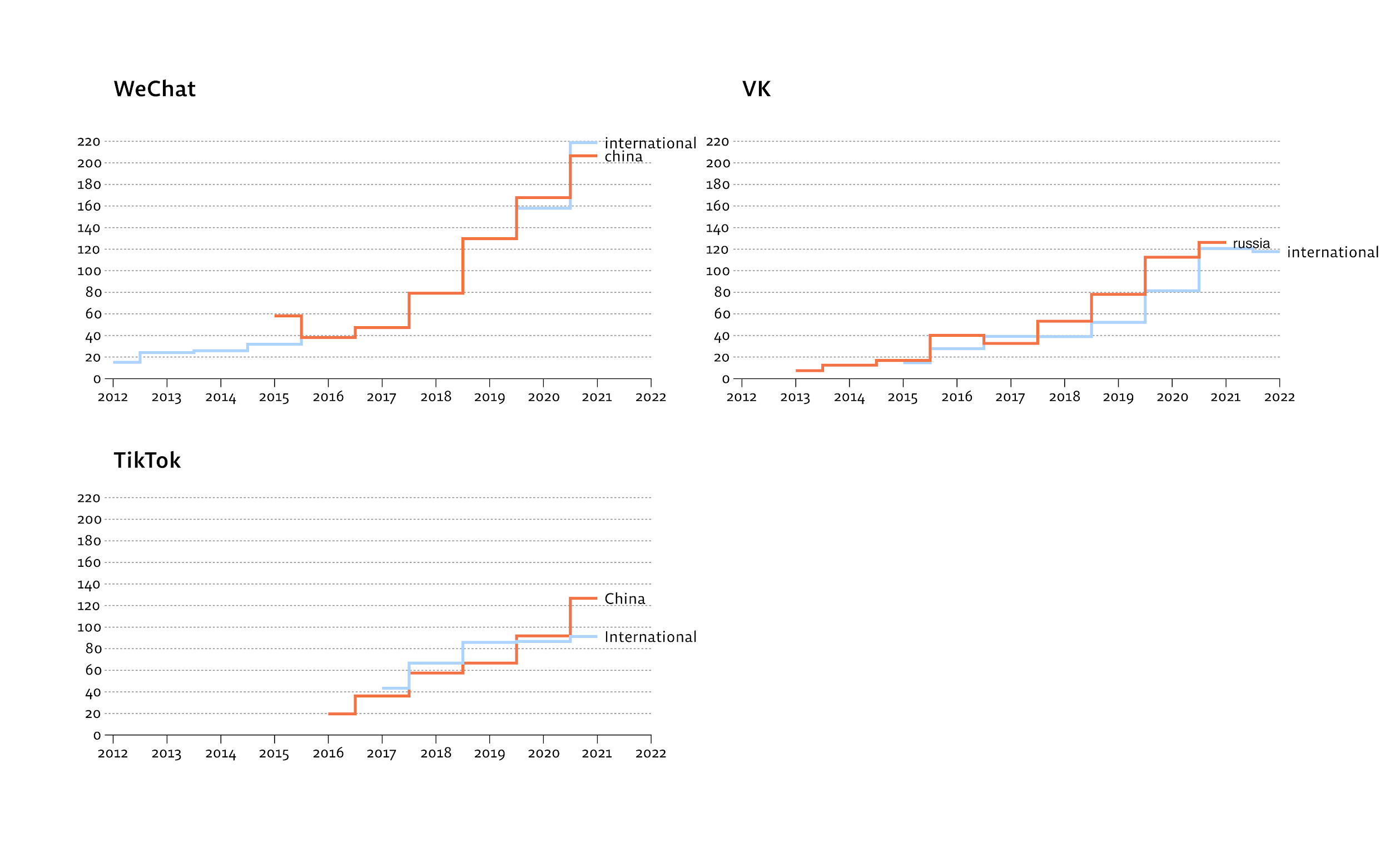
The capability to read sensors changes hands across markets. Scanning Smali for SensorEventListener references over time shows the Chinese TikTok variant retaining sensor-reading code throughout, while the international variant trims it. (On Android, accessing sensors at under 50 Hz does not require a declared permission — so a permissions scan alone misses this.)
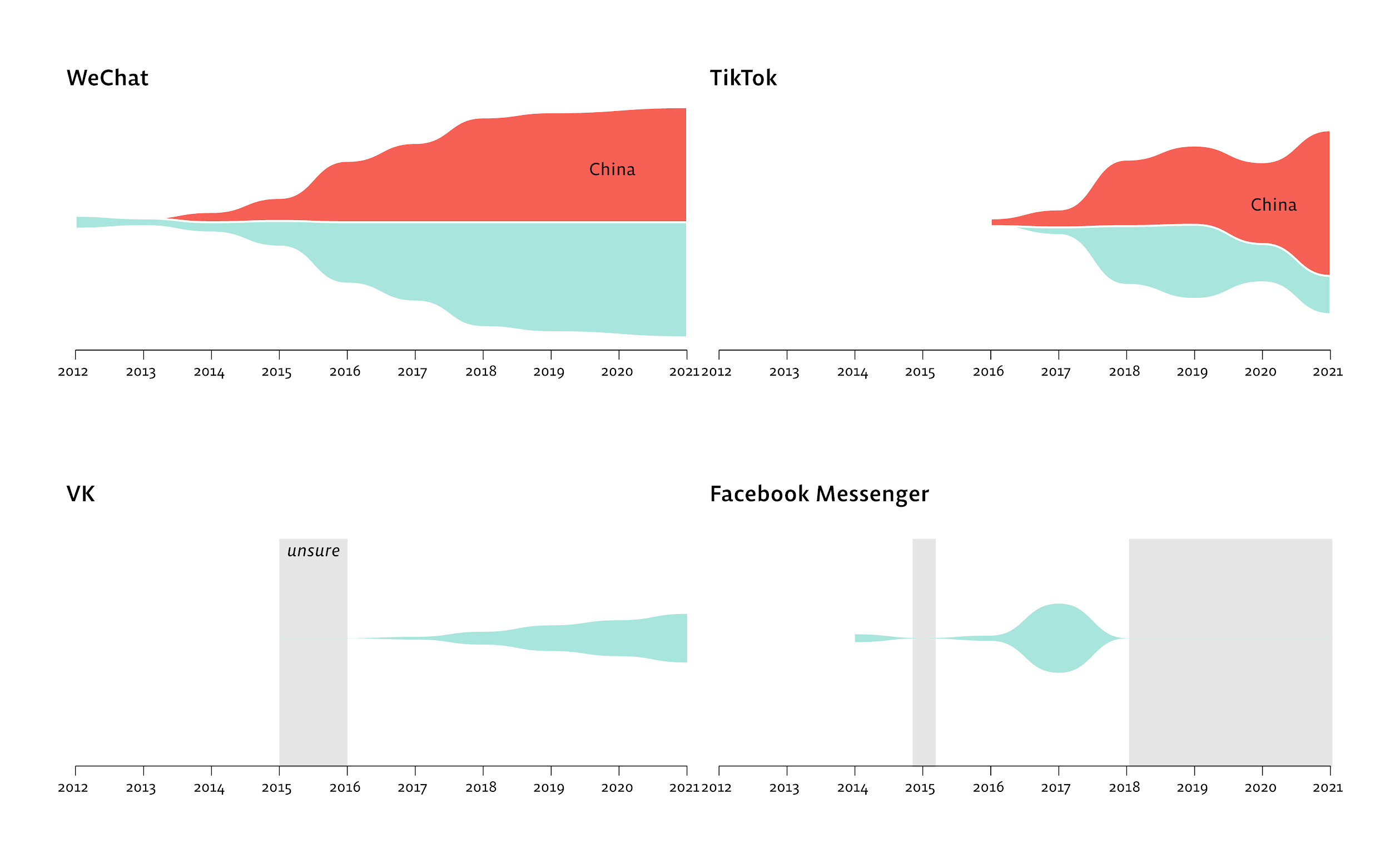
Third-party SDK divergence is immediately visible. A tracker-scan across versions of each app, laid out side by side, shows which SDKs ship in each market:

The underlying query is a few lines of PySpark over the Parquet table:

A specific caveat worth naming: AppInspect is large-scale text search over decompiled bytecode, not rigorous static analysis. No call graph, no data-flow, no taint tracking. Detecting a SensorEventListener reference is detecting capability, not use. Smali strings can be obfuscated, dead-stripped, or loaded via reflection — substring search will miss those.
The distinction matters. “App X contains code that can read the gyroscope” is falsifiable. “App X spies on you with the gyroscope” is not something the tool can show.
What I’d change
I stopped working on AppInspect when I left the SFB in 2024. With hindsight:
- Open-source and containerise from day one. The code is on GitHub, but as a transparency dump rather than a runnable artefact. A Docker Compose stack and a
make demotarget would have multiplied the tool’s reach. - Build a proper benchmark harness. “A few seconds on a hundred APKs” is the kind of claim a reviewer rolls their eyes at. A small script that varies corpus size, partition strategy, and column selection would have produced numbers I could defend.
- Add a thin call-graph layer above the substring index. Even a coarse Androguard-style cross-reference graph, stored as a second table keyed on
(app_id, version_code, class_name), would let researchers ask follow-up questions ("who calls this?") without leaving the tool. - Treat security as an explicit requirement. Running
apktoolon user-uploaded APKs is a sandbox question. We never had an incident, but we never had a real defence either. A gVisor or rootless-Docker per-decode wrapper would have been the right move. - Take the iOS question seriously. A reviewer at RSECon23 asked what it would take to do the same for iOS. The Parquet schema ports cleanly. The decode toolchain (Mach-O, ARM64 disassembly, Bitcode where it survives) does not. It’s a real piece of work, not a porting exercise.
Publication
The design and evaluation of AppInspect and the associated digital-methods workflow are documented in:
Chao, J., van Geenen, D., Gerlitz, C. & van der Vlist, F. N. (2024). Digital methods for sensory media research: Toolmaking as a critical technical practice. Convergence: The International Journal of Research into New Media Technologies, 30(1), 236–263. https://doi.org/10.1177/13548565241226791
AppInspect was built at the SFB 1187 “Media of Cooperation” at the University of Siegen, with collaborators Anne Helmond, Esther Weltevrede, Michael Dieter, and participants of the Digital Methods Initiative Winter School 2022. The TikTok / WeChat / VK / Messenger visualisations were designed by Andrea Benedetti at DensityDesign. Source: jason-chao/appinspect-worker.