A dictionary-natural Wordle solver
Conditional probability over two word lists, plus k-means over character-encoded words to pick openers. No training, no simulations at runtime. Live; talked about at a PyData London Meetup.
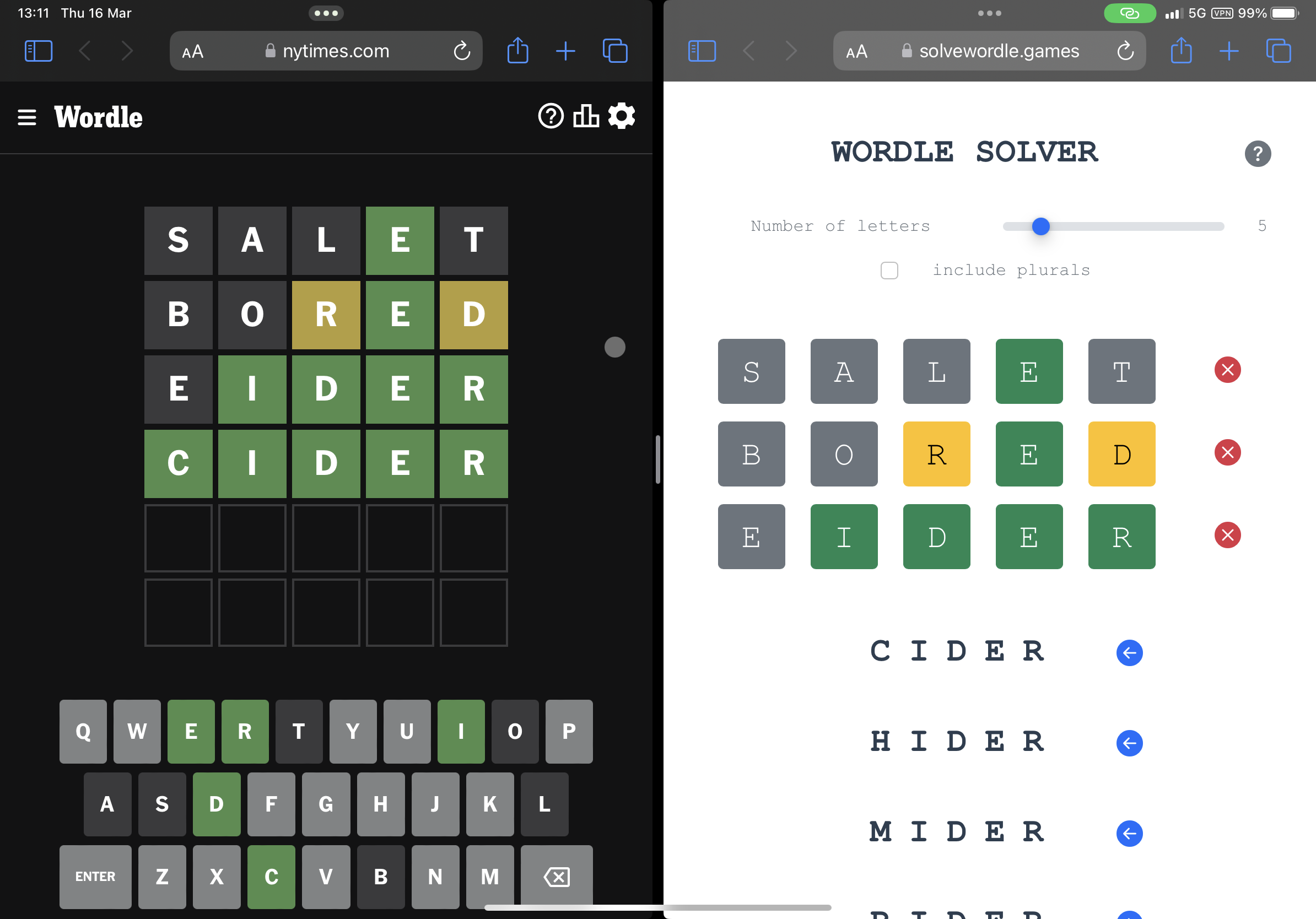
Live at solvewordle.games; talk at the PyData London Meetup, April 2023; code at jason-chao/wordle-solver (117 stars, 22 forks).
Built in 2022 because I do not reliably solve a Wordle in six tries unaided.
The design constraint
No time to train models or run many simulations. That ruled out 3Blue1Brown’s information-theory approach and forced a different one. Three self-imposed rules:
- Future-proof against unofficial Wordle variants with different word lengths.
- Short build time (a few evenings).
- Cheap to deploy (a single-page web UI, no backend fleet).
That meant: no simulation-heavy entropy calculation, no supervised learning, no fixating on the official Wordle answer list.
Two moves that made it work
1. Conditional probability of characters by position. Each round, transform the Wordle feedback into filtering criteria. Rank surviving candidates by the product of per-position character probabilities. A word like alone is scored as P('a' at 1) × P('l' at 2) × P('o' at 3) × P('n' at 4) × P('e' at 5). Intuitive, fast, insufficient on its own.
2. Dual-list switching. Two word lists: MIT’s 10,000 common English words (short, missing some Wordle answers) and dwyl’s 466,000-word corpus (comprehensive, too large to be informative early). The solver uses the short list for the first two guesses, then switches to the long list from guess three.
Opener selection by k-means clustering
Better opening words than the MIT list alone is the unsupervised shortcut:
- Words are segmented by length so vectors share a shape.
- Characters are integer-encoded against a shuffled alphabet array — each letter maps to its index in that array plus one. One integer per character position, not one-hot.
- Scikit-learn’s KMeans:
init='random', n_init=10, max_iter=600, tol=1e-04, random_state=0, algorithm='full'. n_clusters = max(500, int(len(word_list) * 0.12))— roughly 12% of the word list, with a floor of 500 clusters.- Within each cluster, a short in-cluster simulation picks the member producing the widest feedback variety. The union of cluster-best words becomes the curated opener list (written to
english_words_opener.txt).
This gets most of the benefit of the information-theoretic approach without runtime simulation overhead.
Performance
From the repository’s benchmark_results.txt:
The solver also ran on Botfights.ai’s public tournaments — 4th/5th place in the 2,000-word tournament of official Wordle answers (3.6 avg tries, 0.55 behind the champion).
Stack: Vue.js SPA on Google Cloud Storage, Python solver as a Google Cloud Function; live continuously since 2022.
Why the constraint produced a better solver
The entropy-based approach assumes access to the answer list. The dual-list + clustering approach does not. Change the word list or the word length and the solver adapts with no retraining. It runs on a variable-length challenge as cleanly as on the official five-letter version — a property the simulation-heavy approaches do not have for free.